Amazon is one of the most valuable companies in the world because they are one of the best at using data to personalize customer experiences. Amazon collects all kinds of data about you on all of their sites and services; including information that helps predict what you want and need before you even realize it yourself. But Amazon also leverages another kind of data that might surprise you: zero-party data. Zero-party data is more valuable than any other kind because it helps drive better personalization faster than any other data.
To understand the beauty of what Amazon does with zero-party data, we have to take a couple steps back first.
Amazon has built an empire on personalization
As one of the most valuable companies in the world, Amazon is no stranger to personalization. They’ve been using it for years to make sure you get exactly what you want, when you need it. Most of this personalization is powered by data they have collected from observing people using their products over the years. In fact, it’s likely they have over a gigabyte of data about most of the nearly 100 million Amazon Prime members, and quite a bit about everyone else as well.
In fact, their personalization is SO GOOD, they are now offering their recommendation engine as a service through Amazon Web Services (AWS). Their proprietary technology is so successful that other retailers are now looking to emulate them in order to stay competitive: Walmart recently launched a new product line called “Personalized Recommendations by Walmart” which uses machine learning algorithms similar to Amazon’s own; Target has partnered with IBM Watson for their own smart shopping experience; and even Facebook wants to help brands create personalized ads based on users’ interests.
In short, personalization is probably as important to Amazon’s growth as two-day delivery. Which is why I was so excited to see Amazon asking for my preferences and zero-party data the other day!
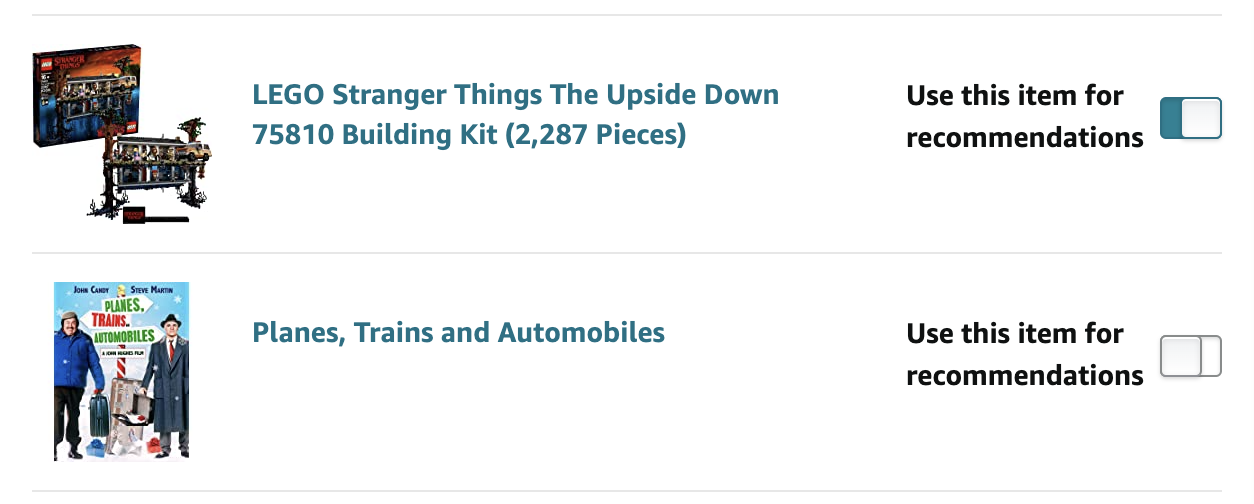
And there are lots of other examples where zero-party data is collected via things like:
- Product Reviews
- Movie and show ratings on Prime, Music, Goodreads, and Audible
- Wishlishts
- Questions and Answers
- Discussions on Twitch
- And much, much more
If Amazon is so good at using our data, why are they asking for more?
The answer to this question lies in a problem Amazon has created for itself. They have over 12 million different products in their store. With all those options, there is a lot of decision anxiety for people making purchases, especially first-time buyers. The more choices we have, the harder it can be to find the right one for us.
What is missing is context. As people, making a decision doesn’t just involve our past purchases and activities, we think about what we need now that is different. That’s what is missing when all you do is look at past behaviors to infer a recommendation. Inferred data leads to errors and risks losing trust, attention, and loyalty—the three most important things any company depends on. A well-designed recommendation system can provide better results than a pure machine learning model by leveraging other information sources (like your purchase history) as well as contextual clues such as your location.
Personalization with Observed vs Declared Data
There are two types of data: observed and declared. Declared data is when you ask someone directly for their preferences and opinions, like in an online survey or focus group. Observed data is more obtuse; it’s got nothing to do with the context of a person’s response, but rather what they actually do on your site—like how long they linger on certain pages or which products they view.
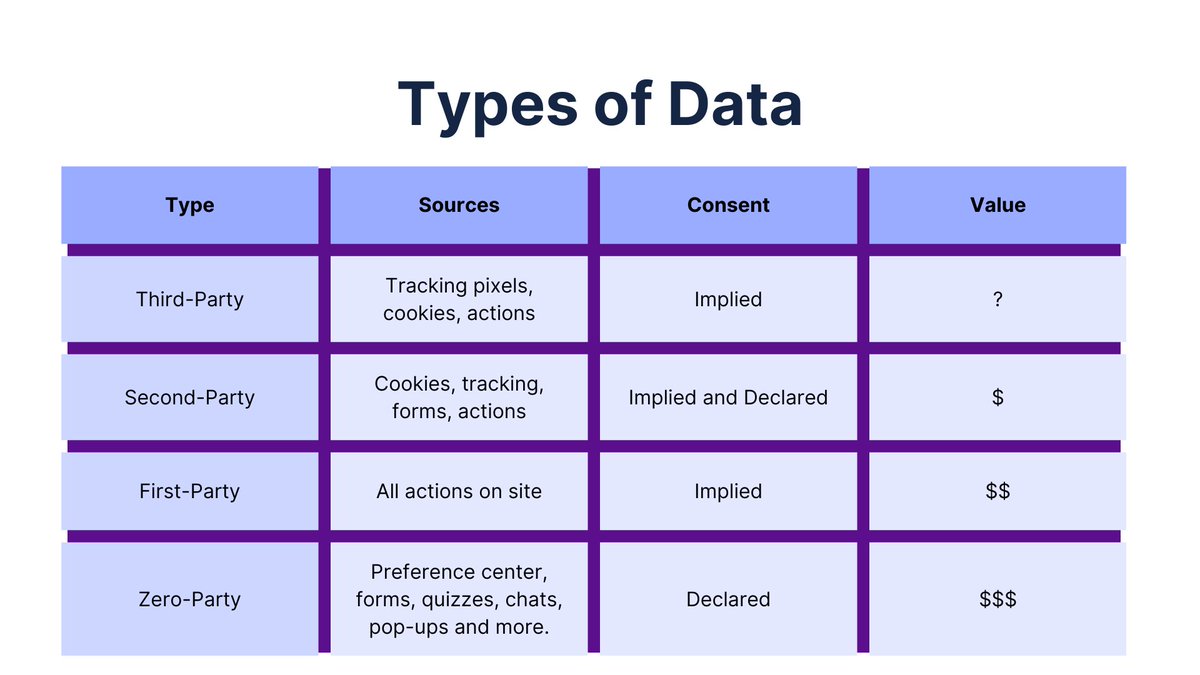
Amazon wants to know as much about your shopping habits as possible so it can use that information to provide personalized recommendations for every customer. But this requires collecting lots of data—and then analyzing it in order to find patterns that will help make those recommendations better. Amazon knows from experience that this type of personalization works best when there are enough customers using the platform over time so that those patterns begin to emerge naturally without having too many outliers skewing the results (e.g., “I only buy one thing ever because I hate everything else”).
Personalization is critical now and in the future
Personalization means tailoring content based on an individual user’s interests and preferences. Using observed data to drive personalization is more expensive and riskier because you don’t know the context of that data. Declared data is all about context because you are asking for what a person wants or needs directly.
Let’s take an example, say you do not have any information about your customers, so you decide to use observed data such as their location and purchase history to place them in segments like “city dwellers” or “country bumpkins” etc. This would be considered a weak form of personalization since it doesn’t give users options for self-expression but rather assumes that there should only be one type of person who lives in the city, who eats organic food, uses public transportation etc., which might not be true for all users! If instead users declare what kind of products they want (such as “I love eating spicy food”) then we could use this declared preference along with other existing contextual information like their location and purchase history to come up with recommendations tailored specifically towards them!
Conclusion
In the end, Amazon is a data company that has built its business around understanding what people want and need to buy. Their recommendations are based on data collected from their customers over time which provides them with a significant advantage over competitors who rely solely on what they think might be relevant. Now that they are adding zero-party, declared data, I expect their recommendations to get even better and that this will be reflected in their growth as a business. We shall see!


